Sizing and Scaling your Optimizer Hub Installation
In order for Optimizer Hub to perform the JIT compilation in time, you need to make sure the installation is sized correctly. You scale Optimizer Hub by specifying the minimum and maximum number of vCores you wish to allocate to the service. The Helm chart automatically sets the sizing of the individual Optimizer Hub components.
Service Scaling
Optimizer Hub can be configured to run with all available services or without Cloud Native Compiler. According to the selected services, different scaling approaches become necessary.
Full Optimizer Hub with Cloud Native Compiler (CNC)
The CNC service must be able to autoscale rapidly to handle resource demands effectively. When under heavy load, for example, during a fleet restart, CNC needs a large amount of resources to be able to perform all requested compilations in time. As such, it must scale up according to the needs, but also scale down quickly when resources are no longer needed as it’s prohibitively expensive to keep those resources always on.
You can control how many compilation requests each JVM can send simultaneously to Optimizer Hub with the compilations.parallelism.limitPerVm setting. This client-side rate limiter prevents any single VM from overwhelming the compilation service. The default value of 500 ensures that VMs do not send more than this amount at the same time, balancing client throughput with server capacity.
Check Compilation Parameters for the available configuration options.
ReadyNow Orchestrator (RNO) Only
When you configure Optimizer Hub in RNO-only mode (using values-disable-compiler.yaml, see Installing Optimizer Hub without Cloud Native Compiler), it does not need to scale. The predefined sizing handles full RNO functionality.
How Optimizer Hub Scales
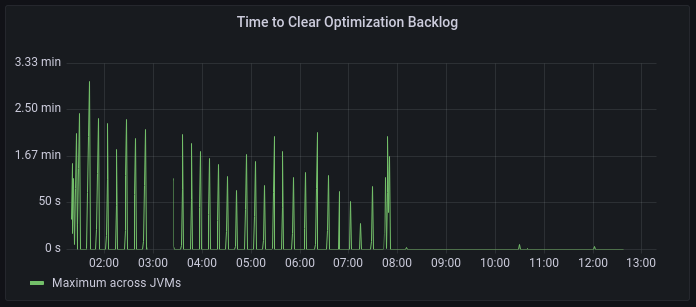
A critical metric to measure whether your Cloud Native Compiler is responding to compilation requests in time is the Time to Clear Optimization Backlog (TCOB).
When you start a Java program, there is a burst of compilation activity as a large number of optimization requests are put in the compilation queue. Eventually, the compiler catches up with the optimization backlog and all new compilation requests start within 2 seconds after the system has put them in the compilation queue. The TCOB is the measurement, for each individual JVM, of how long it took from the start of the compilation activity to when the optimization backlog clears and all requests start within 2 seconds.
Controlling the Scaling with vCores
By default, Optimizer Hub uses autoscaling. You can control autoscaling by specifying the minimum number of vCores for the entire Optimizer Hub installation. The minimum vCores for an Optimizer Hub installation, including a management-gateway pod and one compile-broker pod, is 39 vCores. If you want more compilation capacity, increase minVCores.
The maximum number of vCores, configured by maxVCores, defines the maximum number of vCores over which the Optimizer Hub service does not scale regardless of how much load it is under.
These values can be defined by overriding the default values in your values-override.yaml file. For example, based on your needs, you can configure a higher maximum:
simpleSizing:
maxVCores: 500
Optimizer Hub uses the minimum and maximum number of vCores to adjust the sizing of the instance to try to meet your timeToClearOptimizationBacklog limit for all the JVMs that request compilations.
|
Note
|
Optimizer Hub uses a custom Kubernetes operator to scale and does not use Kubernetes Horizontal Pod Autoscalers. |
Check Simple Sizing Parameters for the available configuration options.
Scaling of the Gateway Service
By default, Optimizer Hub has simple sizing enabled and one Gateway service. Depending on your use case, you can increase this by overriding the default values in your values-override.yaml file.
-
For systems using Cloud Native Compiler (= when you enable all services) that can scale up and down:
-
With simple sizing enabled, an additional Gateway pod requires 7 vCores extra:
gateway: autoscaler: min: 2 simpleSizing: vCores: 46 minVCores: 46 -
With simple sizing disabled:
gateway: autoscaler: min: 2
-
-
For systems with ReadyNow Orchestrator only, which don’t scale up and where simple sizing is disabled:
gateway: replicas: 2
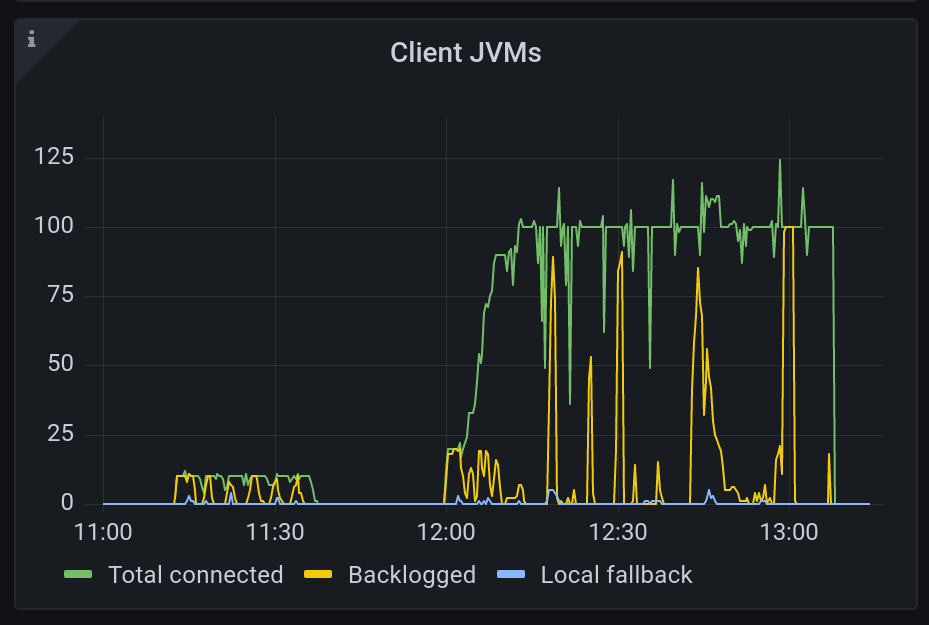
Connection Limit Impact on Scaling
Gateway scaling is not only about CPU and compilation throughput, you also need to take the connection capacity into account. When the per-gateway connection limit is reached, for example, by many long-lived JVM connections, new JVMs cannot connect to the Gateway. If those new JVMs are the ones requesting compilations, Optimizer Hub does not receive those requests and stays at a minimum size even though it needs to scale-up.
You need to configure the minimum number of Gateway instances to guarantee enough connection slots for all concurrently connected JVMs, including JVMs that are currently idle.
See Gateway Connection Capacity for the infrastructure side of this limit.
Scaling API
The Scaling API allows you to instrument Optimizer Hub to temporarily increase the minimum number of vCPUs between a start and end timestamp. Multiple calls can be made to this API and Optimizer Hub takes all given timestamps and potential overlaps into account to start and stop the extra resources.